我们在 I/O 2019 发布了 Benchmark 库的第一个 alpha 版。之后为了能帮助您在优化代码时可以准确地评估性能,我们就一直在改进 Benchmark 库。Jetpack Benchmark 是一个运行在 Android 设备上的标准 JUnit 插桩测试 (instrumentation tests),它使用 Benchmark 库提供的一套规则进行测量和报告:
@get:Rule
val benchmarkRule = BenchmarkRule()
@UiThreadTest
@Test
fun simpleScroll() {
benchmarkRule.measureRepeated {
// Scroll RecyclerView by one item
recyclerView.scrollBy(0, recyclerView.getLastChild().height)
}
}
△ Github 上的 示例工程
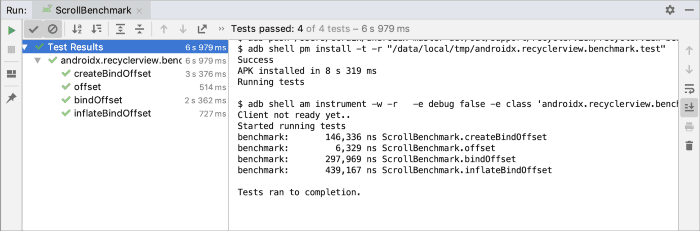
△ Android Studio 输出、运行多个基准测试的示例
Benchmark 库通过它自己的 JUnit Rule API 处理预热、检测配置问题以及评估代码性能。
上面介绍的这些在我们自己的工作环境下用起来很不错,但是很多基准测试数据其实来自于持续集成 (Continuous Integration, CI) 中对于回归模型的检测。那么我们要如何处理 CI 中的基准数据呢?
基准测试 vs 正确性测试
一个工程里就算有数千个正确性测试,也可以轻易通过信息折叠显示在数据面板上。下面就是我们在 Jetpack 中的测试信息:
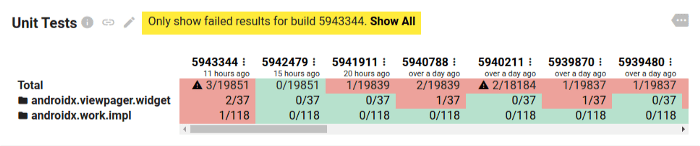
这里没有什么特别的内容,但是在减少视觉负荷方面使用了两个常见技巧。首先,这里以包和类的维度折叠了包含数千条测试信息的列表;然后,默认情况下隐藏了结果全部正确的包。就这样,数十个库里接近两万个测试结果,就被囊括到了寥寥几行文字之中。正确性测试的面板很好地控制了所展示的数据规模。
但是基准测试又如何呢?基准测试不会简单地输出通过/不通过,每个测试的结果都是一个标量,这意味着我们没法简单地将通过的结果折叠起来。我们可以看一看数据图表,也许可以对数据的模式有个直观的了解,毕竟通常情况下,基准测试的数量要远少于正确性测试...
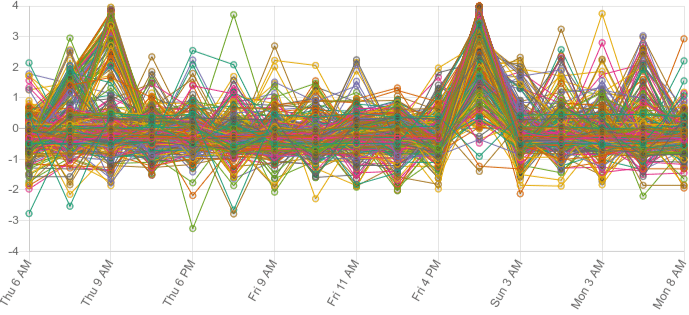
但是您却只能看到一大堆可见噪声。就算测试结果从数千减少到数百个,直接看图表对于数据的分析依然不会有任何帮助。基准测试中保持原有性能结果的数据与测试回归的数据所占据的可视区域相同,所以我们需要把未出现测试回归的数据过滤掉 (这样测试回归的数据才能凸显出来)。
简单的回归检测方法
我们可以从一些简单的事情开始,尝试回到只有通过和不通过的正确性测试。例如可以把两次运行的结果下降百分比超过某一阈值的情况定义为基准测试的失败结果。不过由于方差的原因,这种方式并不能成功。
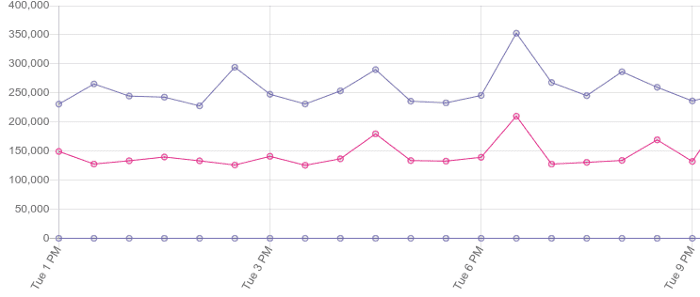
△ 视图填充的基准数据容易出现较大方差,但是仍然提供了有用的数据
虽然我们一直尝试在基准测试中产生稳定且一致的结果,但是曲线的变化仍然会很大,这主要取决于工作量的大小和所运行的设备。比如说,相比于其他 CPU 工作量基准测试数据,我们发现填充视图的测试结果非常不稳定。而将阈值设置为百分之一并不能在每个测试中获得理想的结果,但是我们也不希望把设定阈值的 (或者基线) 的负担施加在基准测试的作者身上,因为这个工作不但繁琐,而且随着分析规模的增加,其扩展性也相对较差。
当一些测试设备在连续几个基准测试中产生异常缓慢的结果时,方差也可能会以低频的大范围波峰的形式出现。虽然我们可以修复其中一些 (例如,防止因电量不足导致核心被禁用时运行测试) ,但是很难避免所有的方差。
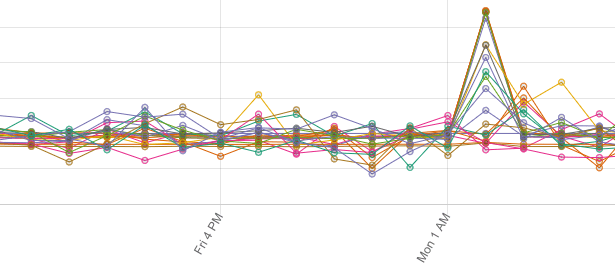
△ RecyclerView、Ads-identifier 以及 Room 的一次基准测试中出现的所有峰值——我们不希望将其作为回归模型报告出来
综上所述,我们不能仅通过第 N 次和 N - 1 次 Build 结果就定位一个测试回归问题——我们需要更多上下文信息来辅助决策。
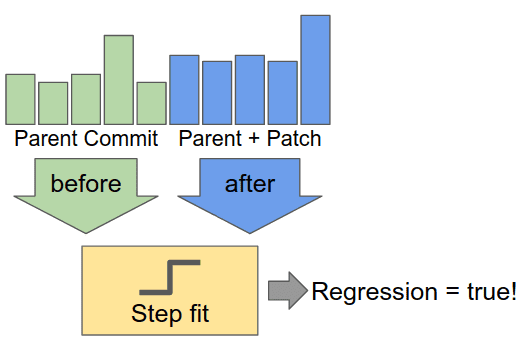
分步拟合,一个可扩展的解决方案
我们在 Jetpack CI 中进行分步拟合的方法是由 Skia Perf application 提供的。
这个方法是在基准数据中寻找阶跃函数。当我们检查每个基准测试的结果序列,可以尝试寻找 "阶跃" 的上升或下降的数据点作为特定的 Build 改变基准测试效果的信号。不过我们也要多看几个数据点,以确保我们看到的是多个结果形成的一致的趋势,而不是偶然现象:
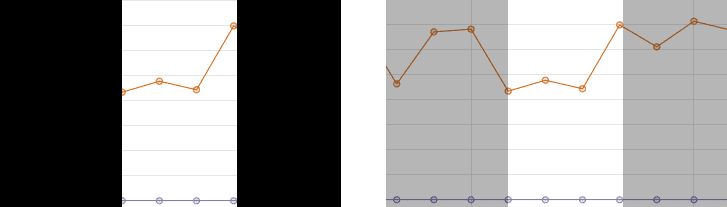
△ 上下文可以揭示出性能退化幅度较大的位置可能只是基准化分析结果反复无常的变化而已
那么我们如何挑选出这样一个阶跃呢?我们需要查看变化前后的多个结果:
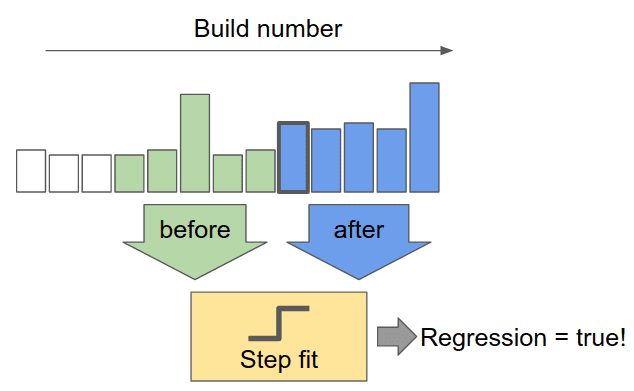
然后,我们用下面这段代码计算测试回归的权值:
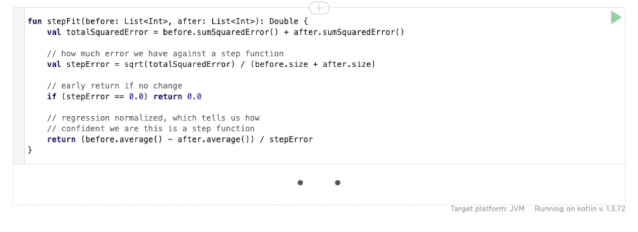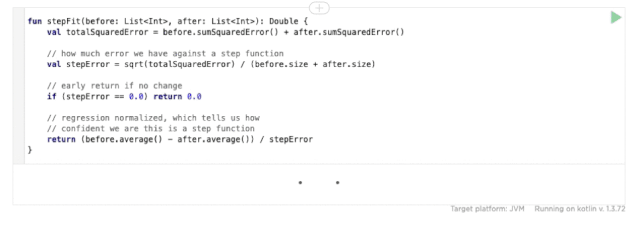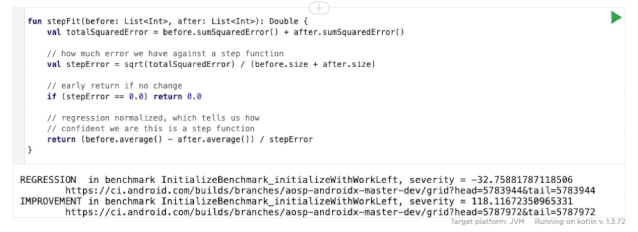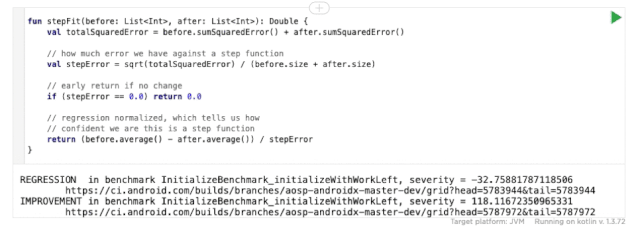
这里操作的原理是,通过检测更改前后的误差,并对该误差的平均值的差进行加权,基准的方差越小,我们就越有信心检测出细微的测试回归。这使得我们可以在一个方差更高的大型 (对于移动平台来说) 数据库基准测试的系统中运行纳秒级精度的微型基准测试。
您也可以自己尝试!点击运行按钮,尝试我们 CI 中处理 WorkManager 基准测试产生的数据的算法。它将输出两个链接,一个指向带有 测试回归 的 build ,另一个指向 后续相关的修正 (点击 "View Changes",来查看该次代码提交的详细内容) 。这些内容与人们在绘制数据时看到的回归和改进相匹配:
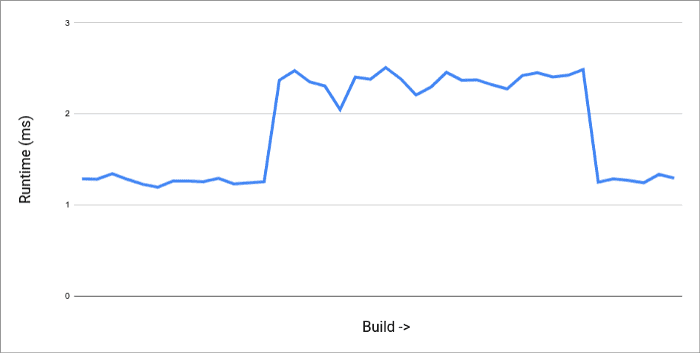
根据我们对算法的配置,图中的所有次要噪声都将被忽略。当它开始运行时,您可以尝试用下面两个参数控制算法:
- 宽度 (WIDTH) — 要涵盖多少个代码提交的结果
- 阈值 (THRESHOLD) — 达到什么程度时会把回归显示在面板上
增加宽度值会降低不一致性,但是也会导致在结果变动较为频繁时难以发现测试回归——我们当前使用的宽度值是 5。阈值用于整体的敏感性控制——我们当前用的是 25。降低阈值可以看到捕捉更多的测试回归,但是也可能导致更多的误报。
如果想在您自己的 CI 中进行配置,需要:
- 编写一些基准测试
- 在真机的 CI 中运行它们, 最好有 持续的性能支持
- 从 JSON 中收集输出指标
- 当一个结果准备完毕时,检查一下当宽度为两倍时的结果
如果有回归或改进,请发出警报 (电子邮件、问题或任何对您有用的措施) 以检查当前 WIDTH 所涵盖的 Build 的性能。
预提交
那么预提交又是什么呢?如果不希望在 Build 中出现测试回归,则可以通过预提交来捕捉回归。在提交前运行基准测试可能是完全防止回归的好方法,但是首先要记住: 基准测试就像 Flaky 测试一样,需要像上述算法这样的基础结构来解决不稳定问题。
对于可能中断提交补丁工作流的预提交测试,您需要对所使用的回归检测有更高的可信度。
由于单次运行基准测试并不能给我们自己带来足够的信心,所以上面的分步拟合算法是必须的。同样,我们可以通过获取更多数据来增加这方面的信心——只需要不加修改地多次运行,来检测补丁是否引入了测试回归即可。
对于每次修改代码然后进行的多次基准测试,都会增加一定的资源消耗,如果您可以接受,那么预提交就能够很好地发挥作用。
全面披露——我们目前没有在 Jetpack 的预提交中使用基准测试,但如果您愿意尝试,以下是我们的建议:
- 不论有无补丁,都要运行基准测试 5 次以上 (后者通常可以缓存,也可以从提交后的结果中获取);
- 考虑跳过特别慢的基准测试;
- 不要阻止基于结果的补丁提交——只需在代码审查期间考虑结果即可。回归有时会作为改进代码库的一部分!
- 要考虑到以前的结果可能是不存在的。预提交无法检测已添加的基准测试。
结论
Jetpack Benchmark 提供了一种从 Android 设备外获取准确性能指标的简便方法。结合上面的逐步拟合算法,您可以解决不稳定的问题,从而可以在性能问题影响到用户前发现它们的测试回归问题——就像我们在 Jetpack CI 中做的一样。
关于从何处开始的注意事项:
- 在基准测试中捕获关键的滚动界面
- 为与第三方库交互的关键位置和高 CPU 消耗的任务添加性能测试
- 要像对待测试回归问题一样对待改进——它们值得深究
延伸阅读
如果您想了解更多,请查阅 2019 Android Developer 峰会中我们的演讲:《在 CI 中使用 Benchmarks》
如果想更多了解 Jetpack Benchmark 是如何工作的,可以查看我们在 Google I/O 的演讲:《使用 Benchmarks 提升应用性能》
我们使用 Skia Perf 应用来跟踪 AndroidX 库的性能,基准测试结果可以在 androidx-perf.skia.org 找到。由于它现在在我们的 CI 中运行,您可以看到此处描述的逐步拟合算法的 实际来源。如果您想了解更多信息,Joe Gregorio 撰写的另一篇有关他们更高级的 K-means 聚类检测算法的博文,解释了 Skia 项目开发的特定问题和解决方案,这些问题和解决方案是专门为整合多种配置 (不同的操作系统和操作系统版本,CPU/GPU 芯片/驱动程序变体,编译器等) 设计的。
版权声明
禁止一切形式的转载-禁止商用-禁止衍生 申请授权
