
作者 / 软件工程师 Santiago Aboy Solanes
Android 运行时 (ART) 执行由 Java 或 Kotlin 字节码。我们不断改进 ART,以生成规模更小、性能更强的代码。ART 贯穿于各个 Android 应用中,因此改进 ART 可以从整体上提升系统性能和用户体验。在本文中,我们将与您分享相关优化环节,在不影响性能的情况下缩减代码大小。
代码大小是我们关注的关键指标之一,因为生成的文件越小,越省内存 (包括 RAM 和存储空间)。随着新版 ART 的推出,我们估计可在每台设备上为用户节省约 50-100MB 的空间。这可能刚好能够满足您更新喜爱的应用或下载一个新应用的需求。由于 ART 可从 Android 12 开始更新,这些优化环节已适用于超过 10 亿台设备,我们在全球范围内为这些设备节省了 47-95 P B (4700-9500 万 GB)!
本文中提到的所有改进均为开源内容,属于 ART 主线更新,因此您甚 至不需要完整地更新操作系统,即可获享这些改进。这些更新能够更好地帮助您高效开发!
优化编译器 101
ART 使用设备端的 dex2oat 工具,将应用从 DEX 格式 编译为原生代码。第一步是解析 DEX 代码并生成中间表示法 (IR)。通过使用 IR,dex2oat 能够执行许多代码优化。对于这个流水线而言,最后一步是代码生成阶段,dex2oat 会在这一阶段将 IR 转换为原生代码 (例如,AArch64 汇编)。
优化流水线包括多个执行阶段,以便每个阶段都专注于一组特定的优化。以常量折叠为例,此优化环节会尝试用常量值替换指令,例如将加法运算 2 + 3 折叠为 5。
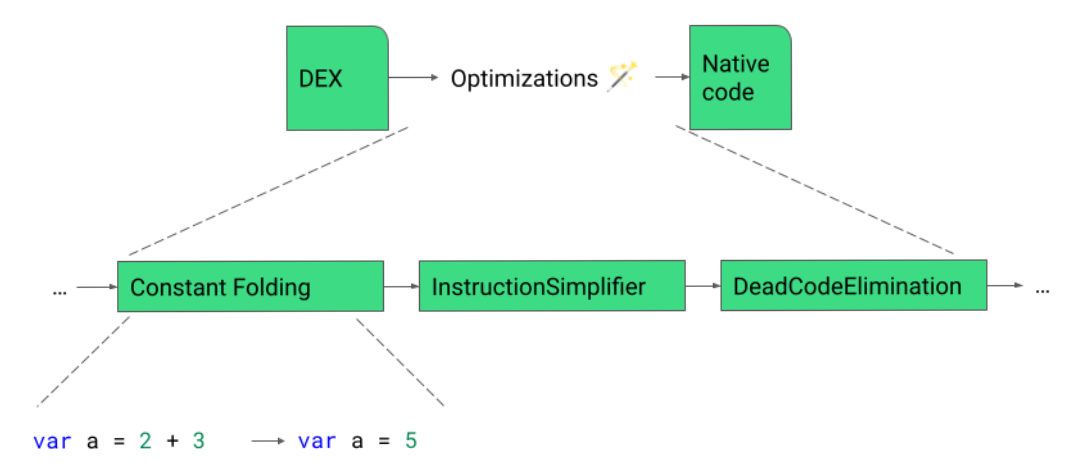
IR 可以被输出和可视化,但与 Kotlin 语言代码相比,IR 非常冗长。在本文中,我们将展示使用 Kotlin 语言代码实施的优化环节,但要知道这些优化是针对 IR 代码进行的。
优化代码大小
针对所有代码大小优化环节,我们对 Google Play 商店中 50 多万个 APK 进行了测试,并汇总了结果。
消除写入屏障
我们推出了名为 "写入屏障消除" 的新 优化环节。写入屏障会追踪自垃圾回收器 (GC) 上次检查以来已修改的对象,以便 GC 可以重新访问。例如,对于以下代码:

过去,我们会为每个对象修改发出一个写入屏障,但实际上我们仅仅需要一个写入屏障,原因如下:
- 标记将在 o 本身中设置 (而非内部对象中);
- 垃圾回收不能与这些集合之间的线程交互。
如果指令可能触发 GC (例如调用和挂起检查),我们将无法消除写入屏障。在下面的示例中,我们并不能保证 GC 不需要检查或改进两次修改之间的追踪信息:

实施这一新优化环节有助于将代码大小缩小 0.8%。
隐式的挂起检查
假设我们正在运行若干线程。挂起检查是我们可以暂停线程执行的安全点 (由下图中的房屋表示)。使用安全点的原因很多,其中最重要的是垃圾回收。当发出安全点调用时,线程必须进入安全点,在释放之前都将处于被屏蔽状态。
在此之前,我们的实现方式是显式布尔检查。我们会加载该值,对其进行测试,并在需要时将其划分到安全点分支。
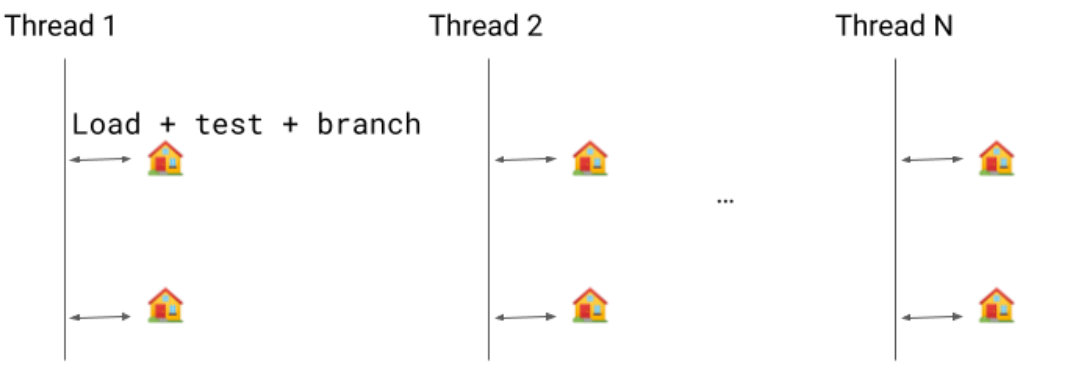
隐式的挂起检查 是一个优化环节,无需测试和分支指令。相反,我们只需要执行加载过程:如果线程需要挂起,该加载会报错,并且信号处理程序会将代码重定向到挂起检查处理程序,就像该方法发起了调用一样。
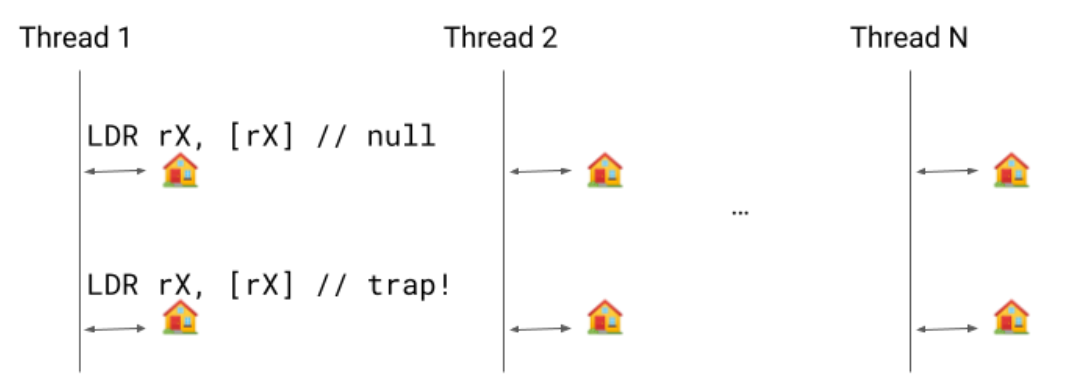
更详细地说,保留寄存器 rX 预加载了线程内的一个地址,其中有一个指向自身的指针。只要不用进行挂起检查,我们就保留该自指向指针。当需要进行挂起检查时,我们会清除指针,在该指针对线程可见后,第一个 LDR rX, [rX] 将加载 null,第二个将出现分段错误。
从本质上来说,挂起请求是要求线程迅速挂起一段时间,因此在等待第二次加载的过程中,出现轻微延迟是可以接受的。
此优化环节可将代码大小缩小 1.8%。
合并 return 语句
已编译方法通常具有入口框架。如果这些方法具备该框架,则需在返回结果时予以解构,这又叫做 "exit frame"。如果一个方法包含多个 return 指令,它将生成多个 exit frame,每个 return 指令对应一个 exit frame。
通过将 return 指令合而为一,我们能够获得一个 return 点,并且能够删除多余的 exit frame。这对于具有多个 return 语句的 Switch/Case 代码特别有帮助。

合并 return 语句可将代码大小缩小 1%。
其他优化环节改进
我们改进了多个现有的优化环节。在本文中,我们将这些优化环节划分在了同一部分中,但实际上它们彼此独立。以下部分中的所有优化环节有助于将代码大小缩小 5.7%。
代码下沉
代码下沉 是一个优化环节,可将指令下推到不常见的分支,例如以 throw 语句结尾的路径。这样做是为了减少在可能不会用到的指令上浪费循环次数。
我们通过 try catch 语句改进了图中的代码下沉:我们现在支持下沉代码,只要不将其下沉到与原始 try 语句不同的 try 语句中即可 (或者,如果代码一开始不属于任何 try 语句,则可放入任意 try 语句中)。

在第一个示例中,我们可以下沉 Object 创建代码,因为我们仅会在 if(flag) 中用到这一语句,而不会在其他路径中使用,并且这二者位于同一 try 语句中。实施这一更改后,在运行时,Object () 只会在 flag 为 true 时运行。在不涉及太多技术细节的情况下,我们可以下沉的是实际的对象创建语句,但是 Object 类的加载仍然位于 if 条件之前。这很难用 Kotlin 代码来展示,因为同一行 Kotlin 代码在 ART 编译器级别会变成多条指令。
在第二个示例中,我们不能下沉代码,因为我们将把实例创建 (可能会抛出错误) 移动到另一个 try 语句中。
代码下沉 侧重于运行时性能优化,但可以帮助减轻寄存器压力。通过使指令更接近其用途,在某些情况下我们可以使用更少的寄存器。使用更少的寄存器意味着更少的移动指令,最终有助于缩减代码大小。
循环优化
循环优化 有助于减少编译时的循环次数。在下面的示例中,foo 中的循环会将 a 乘以 10,循环 10 次。这就相当于将 a 乘以 100。下图使用了 try catch 语句,我们在其中使用了循环优化。

在 foo 中,我们可以优化循环,因为 try 语句和 catch 语句并不相关。
然而,对于 bar 或 baz,我们则无法进行优化。如果循环中有一个 try 语句,或者整个循环都出现在 try 语句内部,那么弄清楚循环将采用哪个路径并非易事。
无效代码删除 – 移除不需要的 try 代码块
我们通过实施优化环节来移除不包含抛出指令的 try 代码块,从而改进了无效代码删除阶段。我们还可以删除一些 catch 代码块,只要没有活动的 try 代码块指向它即可。
在下面的示例中,我们在 foo 中内嵌了 bar。借此知道了该区块无法抛出错误。我们可以在之后的优化环节利用这一点并改进代码。
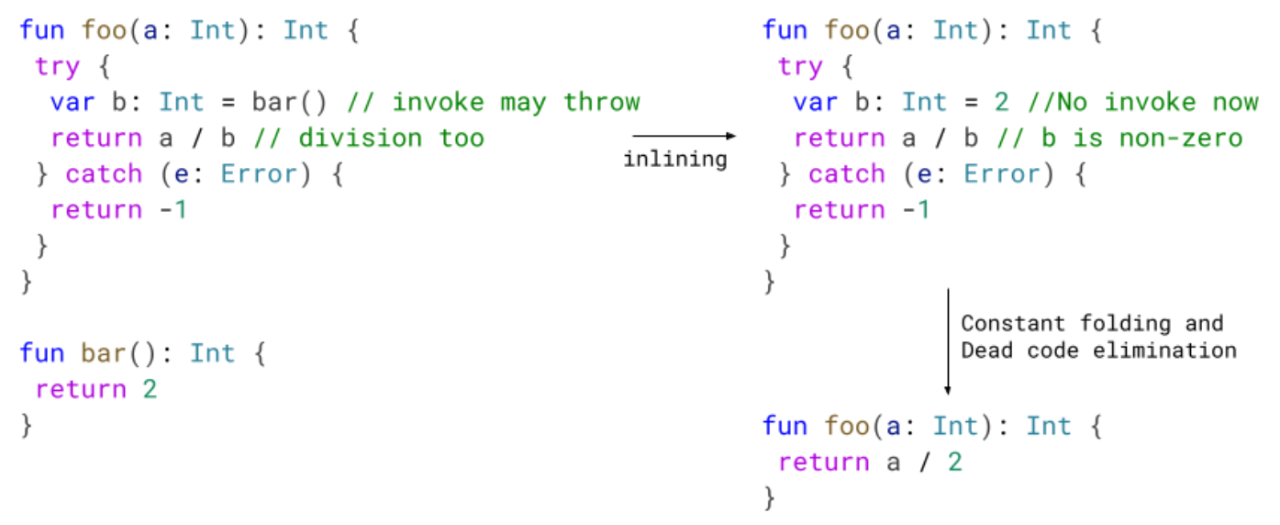
只需从 try catch 中删除无效代码就足够了,不过更好的是,在某些情况下,我们还可以实施其他优化环节。如前文所述,当循环包含 try 或者循环位于 try 内部时,我们不会进行循环优化。通过消除这种冗余的 try/catch,我们可以优化循环语句,生成规模更小和速度更快的代码。

无效代码删除 – SimplifyAlwaysThrows
在无效代码删除阶段,我们实施了名为 SimplifyAlwaysThrows 的优化环节。如果检测到调用总是会抛出错误,我们可以放心地舍弃该方法调用之后的任何代码,因为系统永远不会执行这些代码。
我们还更新了 SimplifyAlwaysThrows,以便处理下图中的 try catch 语句,只要调用本身不在 try 内部即可。如果调用位于 try 内部,我们可能会跳转到 catch 代码块,并且很难找出将要执行的确切路径。

我们还改进了以下方面:
-
通过查看参数来检测调用何时抛出错误。在左侧,我们将 divide(1, 0) 标记为始终抛出错误,即使这种泛型方法并不总是抛出错误。
-
SimplifyAlwaysThrows 适用于所有调用。之前我们会受到限制,例如不要对导致 if 的调用执行此操作,但我们现在可以摒弃所有限制。

加载存储消除 – 使用 try catch 代码块
加载存储消除 (LSE) 是一个优化环节,可移除冗余的加载与存储。
我们改进了这个过程,以处理图中的 try catch。在 foo 中,如果存储/加载不直接与 try 交互,我们可以正常执行 LSE。在 bar 中,如示例所示,我们要么执行正常路径而不抛出错误,在这种情况下返回 1;要么抛出并捕获错误,然后返回 2。由于每条路径的值都是已知的,因此我们可以删除冗余加载。

加载存储消除 – 使用释放/获取操作
我们改进了加载存储消除,来处理图中的释放/获取操作。这些是易失性加载、存储和监视操作。需要说明的是,这仅意味着我们能够在具有这些操作的图中执行 LSE,但我们并不会移除上述操作。
在示例中,i 和 j 是常规整数,而 vi 是易失性整数。在 foo 中,我们可以跳过加载值,因为集合和加载之间不存在释放/获取操作。在 bar 中,这二者之间存在易失性操作,因此我们无法消除正常加载。需要注意的是不使用易失性加载操作并不重要,因为我们无法消除获取操作。

此优化环节同样适用于易失性存储和监视操作 (Kotlin 中已同步的代码块)。
新的内嵌启发法
我们的内嵌过程包含众多启发法。有时我们会因为方法太大而不予以内嵌,而有时会因为方法太小而执行强制内嵌 (例如 Object 初始化这样的空方法)。
我们实现了一种新的内嵌启发法:不要内嵌会导致抛出错误的调用。如果我们知道会抛出错误,我们将跳过内嵌这些方法,因为抛出错误本身的成本很高,所以内嵌该代码路径并不划算。
对于下列三个方法系列,我们会跳过内嵌过程:
- 在抛出错误之前计算并输出调试信息。
- 内嵌错误构造函数本身。
- 在我们的优化编译器中,存在重复的 finally 代码块。一个用于正常情况 (即 try 没有抛出错误),还有一个用于异常情况。这样做是因为在异常情况下,我们必须捕获和执行 finally 代码块,然后重新抛出错误。异常情况下的方法不会被内嵌,但正常情况下的方法会被内嵌。

常量折叠
常量折叠 是一个优化环节,会在可行的情况下将操作转变为常量。我们实现了一个优化环节,传播在 if guard 语句中使用时已知为常量的变量。图中存在多个常量,我们可以在稍后实施更多优化环节。
在 foo 中,我们知道 a 在 if guard 语句中的值为 2。我们可以传播这一信息,进而推导出 b 的值一定是 4。同样地,在 bar 中,我们知道 cond 在 if 分支下必为 true,在 else 情况下必为 false (简化图表)。

汇总
如果我们充分应用本文中介绍的所有代码大小优化环节,我们的代码大小将缩减 9.3%!
从长远来看,一部手机可以有约为 500M-1GB 的优化代码 (实际数字可能会更高或更低,这具体取决于您安装的应用数量,以及您安装了哪些特定的应用),因此这些优化环节可为每个设备节省约 50-100MB 的空间。这些优化环节适用于超过 10 亿台设备,也就意味着这可以在全球范围内节省 47-95 PB!
更多内容
如果您想要了解代码更改本身,欢迎随时查看。本文中提到的所有改进均为开源内容。如果您想帮助全世界的 Android 用户,欢迎您 为 Android 开源项目建言献策:
** Java 是 Oracle 和/或其附属公司的商标或注册商标。*
版权声明
禁止一切形式的转载-禁止商用-禁止衍生 申请授权
